Border Router Performance Optimized Redesign
Author: Justin Rohrer
Last Updated: 2023-05-25
Status: Completed
Discussion at: #4334
Abstract
Right now, the performance of the border router is very much limited because a single goroutine per border router interface is responsible for reading, parsing, processing and forwarding the packets.
Background
The current border router design was not created with performance in mind. Previously, there also existed a design which did something similar than the proposed design in this document. See. Redesigning the current router pipeline is expected to lead to significant performance improvements.
Proposal
The pipeline gets changed to have separate goroutines for the receiving, processing and forwarding steps. This will lead to a much higher performance because the expensive processing logic is moved to other goroutines and to improve the performance we can just increase the number of processing routines. By introducing packet reuse we do not have to allocate memory at runtime to store the packets because we have preallocated memory.
Design
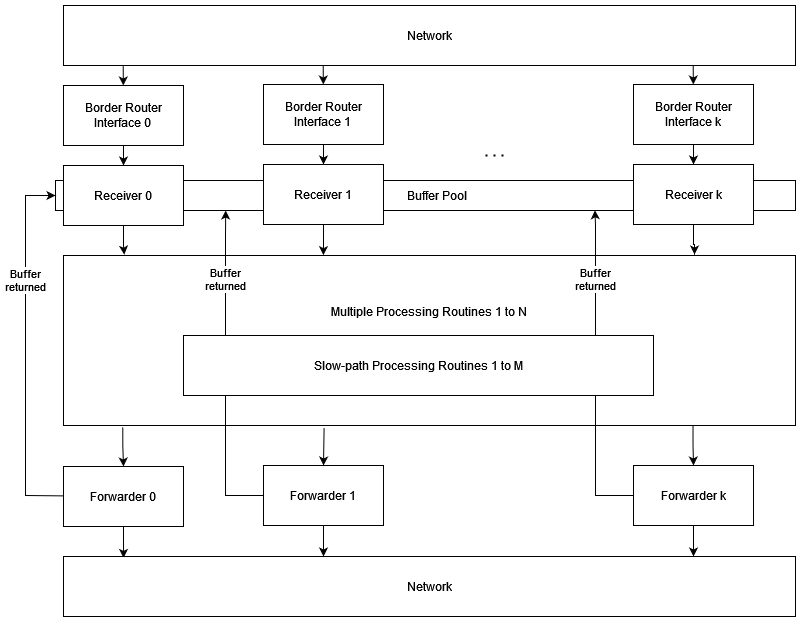
The border router will consist of three layers, the receiving, the processing and the forwarding layer. The communication between those layers are implemented as go channels.
Receivers
There is one receiver per border router interface that is responsible for batch-reading the packets from the network socket, identifying the source and flowID and using them to identify which processing routine has to process the packet. Then the receiver enqueues the packet to that processing routine. If the queue of that processing routine is full, the packet will be dropped. All receivers share a pool of preallocated packet buffers that they can use to store the packets they receive. This can be implemented as a go channel of packets where the receiver reads a certain amount of packets, updates the pointers of the ipv4.Message.Buffers to the buffer inside those packets and then performs a batch read.
Processing Routines
There are several processing routines and slow-path processing routines in the border router that are responsible for processing the received packet. The actual processing logic remains unchanged. If the processing routine identifies a packet that belongs to the slow-path, the processing routines enqueues the packet to a slow-path processing routine. If the queue of the slow-path processing routine is full, the packet will not be processed at all. In this case the buffer is immediately returned to the receivers. Once a packet is processed, it gets enqueued to the forwarder which is responsible for the egress interface. If the queue of the forwarder is full, the packet will be dropped and the buffer returned to the receivers.
Forwarders
There exists one forwarder per border router interface that is responsible for forwarding the packets over the network that it receives from the processing routines. It collects packets from the go channel up to the point where either no further packet is available or the batch size is reached. Then it forwards the packets as a batch. Afterwards it returns the buffers back to the receivers.
Mapping of processing routines
To prevent any packet reordering on the fast-path, we map the flowID together with the full address-header, see SCION header documentation to a fixed processing routine using the fnv-1a hash function together with a random value which is generated on startup to prevent pre-computations of the exact mapping. To mitigate the sticky-zero property of the fnv-1a hash function when hashing, we take the random value first and the flowID and address-header afterwards.
Initial parsing in the receiver
To minimize the time that the receivers need to parse the fields needed to map a packet to a worker we will use a custom parse function that just parses the fields that are needed for the mapping. The values of those fields will be the same as if they would have been parsed with the slayers.SCION parse function.
Slow path
During processing, packets that have to follow the slow path are identified and forwarded to the slow-path processing routines. To do so, we hand over the current buffer to the slow-path routine together with the error codes. Because of that the slow-path processing routine might have to redo some of the parsing if necessary. The original processing routine can immediately continue processing its other packets once it forwarded the slow-path packet to the slow-path routine without the need of doing anything additional compared to the usual packet processing. Rate limiting of slow-path operations is not implemented explicitly, but only implicitly through specifying the number of slow-path processing routines in the configuration. In case a packet is identified to belong to the slow path but the queue of the slow path is full, the packet is dropped. Packets currently identified for slow-path are:
Malformed packets
SCMP traceroute packets
Processor queue size
The processor queue size will be automatically determined as follows:
processorQueueSize := max(ceil(numReaders * readBatch / numProcessors), readBatch)
Pool size
The pool size will be set by calculating the maximum number of packets in-flight through the system:
pool_size := numReaders * readBatch + numProcessors * (processorQueueSize + 1) + numWriters * (writerQueueSize + writeBatchSize)
Configuration
The configuration of the border router will remain in the border router toml file. The following configuration entries are added:
Number of processing routines (N)
By configuring the number of processing routines one can specify the number of goroutines that are able to process packets in parallel. Unlike the other settings, the number of the processing routines are directly taken from the environment variable GOMAXPROCS.
Number of slow-path processing routines (M)
By configuring the number of slow-path processing routines one can specify the number of goroutines that process the packets on the slow-path. An optimal value could be a percentage of the number of processing routines or even a fixed number. A default value would be 1.
Read-write batch size
By configuring the batch size one can specify how many packets are read or written from / to a network socket. A default value for both batch sizes would be 256.
UDP read-write buffer
This setting allows to configure the UDP read and write buffer of the sockets. The actual applied values are subject to the system rmem_max. A default value would be 1MB.
Considerations for future work
Multiple receivers per border router interface
We could deploy multiple packet receivers per border router interface and use eBPF to make sure that all packets that belong to the same flow are received by the same receiver. Because the rest remains unchanged we would still have the “no-reordering” guarantee and significantly increase the read speed.
Lock goroutines to threads
The CPU affinity by locking the goroutines to threads and CPU cores can later be studied.
Replace go channels with custom ring buffer
In the future we might want to replace the go channels that are used for communicating between the goroutines with custom ring buffers in case this provides higher performance.
Traffic control (scheduling)
With the implementation as described in this document the forwarders process the packets from one single queue. In the future we can use additional queues for prioritized traffic between the processing routines and the forwarders. See PR 4054.
UDP generic segment offloading (GSO)
In the future we could add UDP generic segment offloading (GSO) for the connections between border router of different ASes to improve the performance even more. Such an implementation would be feasible in the future because we would just have to identify which border router interfaces are affected and for them make some changes to the IO parts.
UDP generic receive offload (GRO)
In the future we could add UDP generic receive offload (GSO) which seems to better perform than just recvmmsg and would therefore improve the performance even more. Such an implementation would be feasible in the future because we would just have to identify which border router interfaces are affected and for them make some changes to the IO parts.
References
Rationale
One packet pool per receiver vs one packet pool for all
There was the option to use a packet pool per receiver or a larger one for all receivers. The advantage of using a single packet pool for all receivers are that we don’t have to keep track to which receiver the buffer has to be returned and that the total amount of memory we have to allocate would be smaller.
Packet pool as channel vs stack
If we implement the packet pool as a channel we can make use of the fast and optimized implementation by go but if the channel size is too large, the packets might not reside in the cache anymore. On the other hand if we use a stack we would not have the problem that problem but now all goroutines that try to read or write to the buffer pool are now fighting over the lock. Both solutions have advantages and disadvantages but I would suggest to implement it as a queue because go already provides a good implement for that and if we later realize that the other solution would lead to better performance, we could still change it.
Compatibility
This is not a breaking change, just a performance improvement. All other components will be able to interact with the border router the same way as before.
Implementation
The implementation as suggested in the design document can be implemented in separate pull request to make them easier to review. All those changes below should lead to a border router following this design document.
Restructure the router/dataplane.go file to have a reading, processing and forwarding functionality together with buffer reuse support
Add slow-path support
Add configurability for the new functionalities